All published articles of this journal are available on ScienceDirect.

Research and Implementation of Children’s Speech Signal Processing System
Abstract
As people's living standard and the degree of mass culture have been constantly improved, many families are caring more about the healthy growth of early childhood. In this paper, based on the research of domestic and foreign experts and scholars: the guardians (such as parents) take appropriate intervention on children at the early stage can effectively promote children's language and cognitive ability development, and the intervention has obvious effect on the autistic spectrum disorders of children. This paper presents a system for analyzing children's speech signal, calculating the guardian’s language words, the number of children‘s verbal words and the number of guardian and children's dialogue rotation times by voice signal processing and pattern recognition technology. And related personnels use these indicators to analysis the development of children's language and cognitive ability, then adopting appropriate measures for children and providing the basis for decision-making criteria, so as to promote the development of children's language and cognitive status.
1. INTRODUCTION
More and more families are paying close attention to the healthy growth of children, studies of children's language and cognitive development are also quite a lot. T.R. Risley et al. [1] found in the language development of children: (i) the variation in children’s IQs and language abilities is relative to the amount parents speak to their children, (ii) children’s academic successes at ages nine and ten are attributable to the amount of talk they hear from birth to age three. and (iii) the parents of advanced children talk significantly more to their children than parents of children who are not as advanced. Also related studies show that a positive response behavior to children throughout the early child development, which have an beneficial effect on children's language, cognition, social and emotional behavior [2,3]. In [4], research suggests that a young child’s ability to use language, as well as attune to and understand the meaning of spoken and written words, is related to later achievement in reading, writing, and spelling. Studies also show that children from low-income families are both spoken to and read to less frequently than their middle-class peers, which hinders their ability to develop literacy and language skills. This leads to the widening achievement gap or “language gap”. In addition, Autism Spectrum Disorder (ASD) has gained more and more attentions in recent years, it is important for young children’s early diagnosis through the early intervention services [5,6]. In recent years, with the understanding of children's language development law, workers who pay attention to children’s language development are more and more urgent to need artificial intelligence technology to automatically monitor and identify children's language development situation.
At present, there are lots of researches on speech recognition, speech synthesis and other aspects, and related technologies are also more and more mature. But researches by using speech signal processing technology to analyze and detect early childhood language development are relatively less. In the study of foreign representative is LENA (Language Environment Analysis) foundation [7], which has put forward the evaluation system of children's language development. There are some differences in environment, language and so on between English and Chinese. For example, English word is composed of vowel and consonant, but Chinese character is composed of initials and finals. So LENA system has not yet been widely used in China.
While at home the researches and applications in this area have not been readily available for reference model, we study the characteristics and knowledge of early language interaction between parents and children on the above scholars by means of combining speech signal processing and pattern recognition technology to do some exploration and research work in this regard. In this paper, we propose a system about automatically processing children’s speech signals for subsequent analysis and study. The voice signal is collected in the family environment through the digital voice recorder. The signal will be segmented into guardian, target children, and noise part after preprocessing, classification and other key steps. Then the language words of the guardian, target child and the number of dialogue between guardian and target child will be obtained respectively by pattern recognition technique. Relevant personnel will evaluate children's speech development situation according to these indicators, and then the result will feed back to the guardian (parents), to make them understand the development of the children's language and cognitive ability. If the results are poor, it will remind the guardian (parents) to take appropriate intervention measures to improve the situation, such as strengthening communication times with children. And later work to evaluate and intervene on the basis of these indicators will be done by other researchers, including the standard of evaluation. All of these work are not within the research of this paper, this system only give calculation results of each index.
The rest of this paper is organized as follows:
The second part, the general description of speech signal processing system proposed in this paper. The third part, each subsystem is described in detail; The fourth part, the experiment data and the platform is introduced; The final part, the result is summarized and discussed.
2. OVERALL DESIGN OF SYSTEM
The overall design idea of the speech signal processing system block diagram proposed in this paper is shown in Fig. (1).
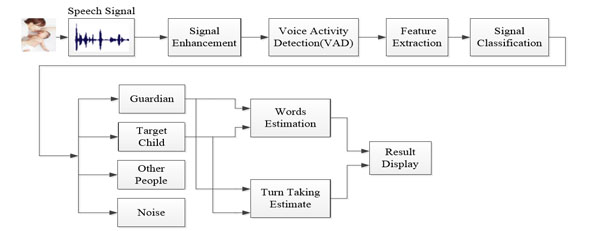
Functional block diagram of the overall design.
Effective speech detection.

Signal classification system.
Signal classification results Signal classification results

Word count system.
Segmentation results.
| Indexes | RCL | PRC | F |
|---|---|---|---|
| Values | 0.83 | 0.80 | 0.81 |
Error rate comparison.
| categories | Werror | Derror |
|---|---|---|
| Programme 1 | 23% | 17% |
| Programme 2 | 28% | 19% |
First we acquire the speech signal of the target child (study object) in the actual environment (mainly refers to the family environment). The speech signal is collected by special digital voice recording system. Then extracting the feature vectors which are easy to distinguish between different speakers, or the characteristics of the signal source to facilitate speech signal classification latter. According to the target children's environment, the system signal is divided into four categories: the guardian, the rest of the population, noise and target children. The guardians mainly refers to the people who look after child in the family; other personnel refers to the non-fixed population differs from the guardian, such as guest of adults or other children; noise mainly refers to the multimedia signal, such as television, telephone, toys etc.
Single speech signal of guardian or child is used for counting words respectively, and counting the number of dialogue between them by using the method of pattern recognition. Then related workers make use of these indicators to analysis the children’s language development.
The following content is the detailed description of the algorithm implementation for each sub-module.
3. IMPLEMENTATION OF SUBSYSTEM
3.1. Speech Signal Enhancement
In order to improve the recognition rate and anti-jamming capability of the system by adding signal enhancement part in speech signal processing. The method based on minimum mean square error (MMSE) due to its outstanding noise reduction effect and less speech distortion, this paper adopts its derivative algorithm, which is to use the estimator of the logarithm spectrum minimum mean square error [8]. The collected signal will conduct early enhancement processing to improve overall performance and accuracy of the system.
3.2. Voice Activity Detection
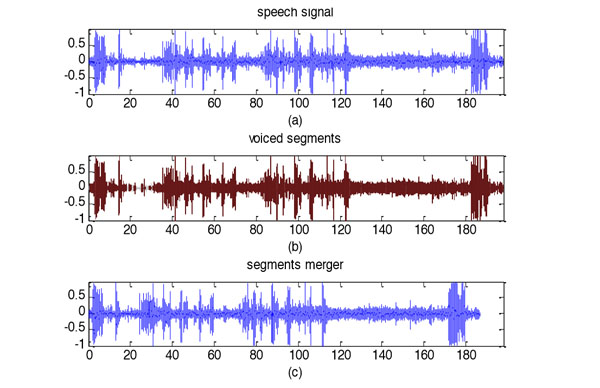
Voice activity detection is to distinguish the effective voice parts and non-speech parts of speech signal. The analysis of the system need to remove the non-speech part of signal, which includes silence, music and background noise, etc. This algorithm is based on the characteristics of spectral centroid and short-time energy to detect effective speech segments in the speech signal, then merging to form a new speech signal.
Fig. (2) is the application of this algorithm, the speech signal we selected is about 3 minutes (Note: In order to make the signal waveform can better display, the speech signal in this paper, a short time to display the waveform of the signal system, but using a longer time in the actual situation), which is obtained from Shanghai Children's Medical Center. Among the Fig. (2), (a) is representative of the original speech signal in time-domain, (b) represents the detection result (red part is useful.) and (c) represents all the effective signal after merger.
3.3. Extracting Feature Vector
Although this research is mainly aimed at family environment, but the signal collected by digital recorder is quite vast and complex. So in order to make the above four kinds of signal separated well, feature vector selected whether is reasonable concerns the performance of the whole system to achieve the desired effect.
In the current speech recognition system, due to the high–level speech characteristics (e.g. clarity, amplitude, hoarse degree, the level of activity and accents, etc.) are difficult to extract, so most of the characteristic parameters used are low-level acoustic characteristics, such as common Linear Predictive Cepstrum Coefficient (LPCC) [9], Mel-Frequency Cepstrum Coefficient (MFCC) [10] and the Perceptual Linear Predictive coefficient ( PLP) [11].
This paper selects the features of time and frequency domain characteristics. We extract feature vectors for each frame by framing and windowing, the time domain features are one parameter of the zero crossing rate, one parameter of energy and one parameter of entropy of energy; frequency spectrum feature vectors are one parameter of spectral rolloff, two parameters of spectral centroid and spectral spread, one parameter of spectral entropy, one parameter of spectral flux, thirteen parameters of mel-frequency cepstrum coefficients and one parameter of fundamental frequency.
3.4. Signal Classification
In this paper, the method of classification in system is to use the speaker change point detection method to divide speech signal into many small voice, then adopting a bottom-up clustering to merge the same speaker parts together.
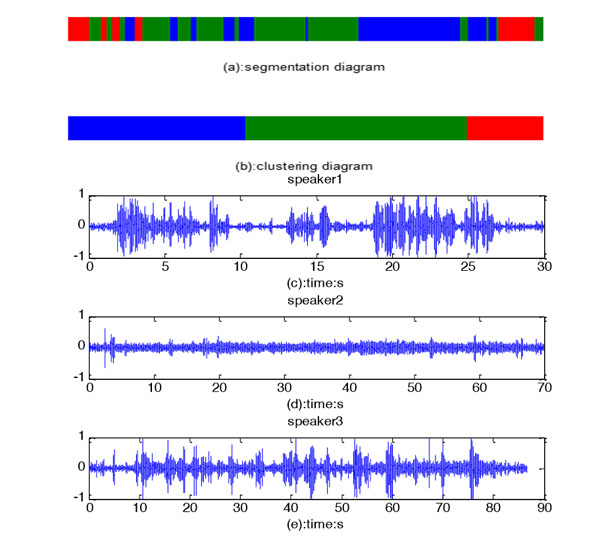
The proposed system block diagram of classification as shown in Fig. (3), there are mainly four modules, which are the feature vector extraction of the speech signal, similarity measurement, speaker change point detection and clustering corresponding speech segments.
This system in the evaluation of segmentation part mainly has three parameters: the recall rate (RCL), namely the percentage of truly detected speaker boundaries; precision (PRC), that is, percentage of candidate speaker boundaries which are the actual speaker change points; comprehensive performance measure F (F-measure). These parameters are defined as follows:
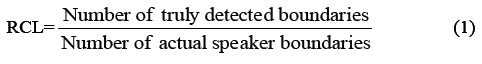
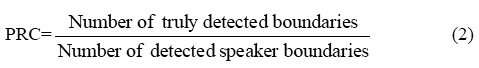
To consider the trade-off between these two metrics, the harmonic mean of these two metrics is used as the total evaluation criterion:

The higher RCL, PRC and F are, the better is the performance.
The signal we select to make the experiment of speaker classification is the ‘segments merger’ signal, which is obtained from the part of voice activity detection. In the Fig. (4), from top to bottom, (a) shows three types of signal after segmentation, where the colours of red, yellow and green represent three different people(child, father and grandmother). (b) represents the clustering results of the same type of signal. (c), (d) and (e) show time-domain waveform of each speaker respectively.
We use RCL, PRC and F to evaluate the algorithm of segmentation in this paper. The best results is recorded as shown in table 1. From the results it can be known that the segmentation algorithm is good, which is conductive to the latter operation.
3.5. Word Count
Adult language words have a significantly positive correlation effect on the language development of children.
In this article, we adopt the speech rate calculation method put forward by Dagen Wang and Shrikanth S. Narayanan [12] to calculate the number of adult or children’s words. The core of the algorithm consists of four parts: spectrum, time domain processing, smoothing and threshold setting. Since a syllable is a word in Chinese, the rate obtained is the word rate, then it is easy to convert the result to the number of words. The innovation of this algorithm is to add secondary voice activity detection and the second speech enhancement. Word count system as shown in Fig. (5).
In this system, the estimation of the number of words is composed of three parts: secondary voice activity detection, the second speech enhancement and syllable calculation. Where the secondary voice activity detection and the secondary speech enhancement parts are the second time of signal processing in voice activity detection and speech enhancement in order to improve the accuracy of calculation. We use the syllable detection technology proposed by Wang and Narayanan Syllable on the calculation of basic system, the technology is mainly relies on the signal peak detection to find syllables in speech signal.
3.6. Dialogue Frequency Calculation
In this study, the annotation of a dialogue is: adult (or child) make a response at the end of a child’s (or an adult’s) speech, which we denote one time of conversation.
The specific idea is: in the process of speech signal classification, when a child's speech segmentation point appears we consider it a dialogue. Then we compute the entire times in the similar way.
4. THE EXPERIMENTAL DATA AND PLATFORM
4.1. The Experimental Data
The data source which is applied by language development department of Shanghai Children's Medical Center which has contacted related families. Speech recording is children’s all day activity time, approximately 16 hours. The data sampling frequency is 16 kHz, the precision is 16bit. We choose the data source is general, namely family selection is random, the voice is also under the natural scenes of life.
4.2. The Experiment Platform
Operating system: Windows 8 professional edition, 64-bit; Processor: AMD E-450 APU with Radeon™ HD Graphics, 1.65 GHz; Memory: 4.00 GB; Software: MATLAB 2012(a).
5. RESULTS AND DISCUSSION
In order to evaluate the actual performance of this system, we define words calculation error rate:

In the Eq. (4), ActualW and CalculatedW represent the actual number of words and calculated amounts respectively.
Error rate of dialogue frequency calculation:
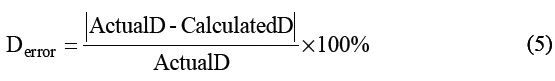
In the Eq. (5), ActualD and CalculatedD represent the actual number of dialogues and calculated amounts respectively.
According to many experiments, at best, Werror and Derror can be reduced to 23% and 17% respectively. In table 2, we make a comparison about experiment results between the programme 1 (system with secondary signal enhancement and voice activity detection) and the programme 2 (system without secondary signal enhancement and voice activity detection). It concluded that the former result is better that the latter one.
Table 2 shows that, the performance and accuracy of the entire system is improved after adding the secondary signal enhancement and voice activity detection parts.
We can see from the experimental results, after the pretreatment (including signal enhancement, voice activity detection), whether classification results or the later words count, the results are quite satisfactory compared with the actual situation. After adding the process of the secondary signal enhancement and voice activity detection, the calculation results have been improved.
CONCLUSION
To sum up, according to related literatures in the field of children's language development, we proposed the automatic measurement technology to count a few indicators affecting the formation of children's language. It is also a possible way to detect the children with Autism Spectrum Disorder (ASD). And it can detect such flaws in the aspect of language development as soon as possible for early treatment, to improve children's language development and language cognitive ability.
However, we have a lot of related works to do and hope to make a big breakthrough. In the future, we will try to do some evaluation works in our system to realize truly automation of children’s speech signal processing.
CONFLICT OF INTEREST
The author confirms that this article content has no conflict of interest.
ACKNOWLEDGEMENTS
The authors would like to thank all colleagues who are involved into this study. At the same time we thank the support from Shanghai Committee of Science and Technology.

