All published articles of this journal are available on ScienceDirect.

A Survey on Deep Learning Models Embed Bio-Inspired Algorithms in Cardiac Disease Classification
Abstract
Deep learning is a sub-field of machine learning that emerged as a noticeable model in the world, specifically for the disease classification field. This work aims to review the state-of-the-art deep learning models in Cardiac Disease prediction by examining several research papers. In this study, popular datasets listed and analyzed in the prediction process of cardiac disease with their performance using various deep learning techniques are presented. This review emphasizes the latest advancement in the six deep learning models, namely, deep neural networks, convolutional neural networks, recurrent neural networks, extreme learning machines, deep belief networks, and transfer learning with its applications. The important features of cardiac disease used by five different countries have been listed that guide researchers to analyze it for future purposes. Freshly, deep learning models have yielded an extended performance in cardiac disease detection that shows its rapid growth. Specifically, deep learning effectiveness concerted with the bio-inspired algorithms is reviewed. This paper also presents what major applications of deep learning techniques have been grasped in the past decade.
1. INTRODUCTION
People throughout the world have battled several deadly illnesses over the years, with heart disease [1] garnering the most attention in medical studies and has reached a great deal of observance in medical research. It is one of the prominent diseases that affect many people during their middle or old age, and in several cases, it eventually leads to fatal complications. Heart diseases are more habitual in men than in women. The diagnosis of heart disease [2] is very important in the prediction process. A timely diagnosis of heart disease is crucial in reducing health risks and preventing cardiac arrests. Some of the risk factors [3] faced by people that will rapidly increase heart diseases are smoking, gender (Sex), age, ethnicity, family history of the disease, high blood pressure, high blood cholesterol, diabetes, poor diet, lack of exercise, obesity, stress, and vessel inflammation. The World Health Organisation (WHO) [4] lists Cardiovascular diseases as the leading cause of death globally, with 17.9 million people dying every year. A pertinent threat endured by healthcare organizations, such as hospitals and medical centers, is the allocation of worthwhile amenities at moderate costs. Due to the lack of healthcare services from a physician, the need for an automatic diagnosis system emerged with artificial intelligence as a root concept, where then machine learning came into the picture with a lot of models focused on various human health-related problems. For more computational performance in diagnosing cardiac disease classification type, a contrast to traditional machine learning methods, deep learning technologies have recently emerged with support from bio-inspired algorithms that are mainly used for solving optimization problems.
The deep learning concept was first initiated by Walter Pitts and Warren McCulloch [5] in the year 1943 through a computer model that is based on the neural networks of the human brain. With the continuation of the existing model, Henry J Kelley [6] developed Back Propagation Model in 1960, and the simpler version of it was developed by Stuart Dreyfus [7] in 1962 and is based on the chain rule. Both of these models were inefficient and not be utilized in the research until 1985. An effort has been taken to develop deep learning algorithms by Ivakhnenko and Lapa [8] in 1965 with models of concept from polynomial activation functions. Later, in 1979, the first convolutional neural networks were used by Kunihiko Fukushima [9], who developed an artificial neural network that is named Neocognitron, which is used to recognize visual patterns. Neural networks and deep learning-based research emerged in the year 1985 to 1990, with the invention of the Support Vector Machine by Dana Cortes and Vladimir Vapnik [10] in the year 1995 and Long short-term memory in 1997, by Sepp Hochreiter and Juergen Schmidhuber [11]. With the adoption of Graphics Processing Units [12], there was a significant advancement in deep learning for the process of better and faster results. The influence of deep learning in the industry began in early 2000, with the vanishing gradient problem [13], and it was solved by layer-by-layer pre-training and LSTM. In 2009, Fei-Fei Li [14] launched ImageNet, a free database that is used for storing more than 14 million labeled images that are useful for training neural nets. Deep learning significantly held high efficiency and speed in the year 2011 and 2012, to the speed of GPUs [15] and with the invention of AlexNet, a CNN-based architecture developed by Krishevsky et al . [16]. Table 1 list the history of deep learning models. Deep learning has several other application areas, such as cybersecurity [17], the agriculture sector [18], and power expansion planning [19].
Bio means 'life' described from the Greek root word and contributes up mostly to terms from the domain of the 'life' sciences. Further from bio, the next important concept in biology (or bio) classes, which it guides to learn all about 'life.' Biological processes work with the way 'living' organisms function. A biography (or bio) is defined as a dissertation that tells all about the events in someone's 'life’, drafted by some writer other than the subject of the 'life' history. Bio-inspiration [20] is the blooming of modern structures, resources, and methods. It is stimulated by results found in adaptation, procedures, and salvation, which has biologically progressed over millions of years. The concept is to enhance the sculpting and replication of the biological system to better understand nature's analytical constructional features, such as an extension, for use in bioinspired design advancement. Biomimicry varies from bioinspiration by the replication of the designs in biological materials. Bioinspired can also be defined in research areas such as in the elegant ancestry of science: it is a glebe based on the remarkable functions by perceiving it to characterize living organisms and mimic those functions with the usage of abstraction. It has the strategy of solidity in the establishment of chemistry with the approach of substream. Notably, this research is still an emerging model with its technological and scientific systems, academics, and industrial levels. The bio-inspired field started in the early 1980s and 2010s with many types of research on the natural phenomenon in limited support, but in 2020 it was a huge growth in the variety of novel algorithms that have been defined successfully.
| Year | References / Authors | Models | Contribution / Use |
|---|---|---|---|
| 1943 | Walter Pitts and Warren McCulloh | Neural Network | They have utilized the threshold logic to mimic the thought process |
| 1958 | Frank Rosenblatt | Multi Perceptron | It consists of multiple layers of neurons used in computational neuroscience. |
| 1960 | Henry J Kelley | Back Propagation | It is used to train feedforward neural networks and compute loss functions concerning the weights |
| 1970 | Kunihiko Fukushima | Convolutional Neural Network | It is used for classifying images and recognizing patterns |
| 1979 | Kunihiko Fukushima | Artificial Neural Network called “Neocognitron” | It is also used to recognize the visual patterns |
| 1985 | Geoffrey Hinton and Terry Sejnowski | Boltzmann Machine | It does not expect input data, and automatically generates data regardless they are hidden or visible |
| 1986 | Paul Smolensky | Restricted Boltzmann Machines | It can be trained in supervised or unsupervised learning ways. |
| 1989 | Yann LeCun | CNN with BP | It is developed to read handwritten digits |
| 1995 | Dana Cortes and Vladimir Vapnik | Support Vector Machine | It is a system used for mapping and recognizing similar data |
| 1997 | Sepp Hochreiter and Juergen Schmidhuber | Long Short-Term Memory and Recurrent Neural Network | It is designed to learn sequential data and able to solve vanishing gradient problem |
| 1998 | Yann LeCun | Gradient-Based Learning | It is an optimization algorithm used to solve the local minimum problem |
| 1999 | Nvidia | GPU processing for speed | It can process many data simultaneously, which makes performing machine learning and gaming so easier. |
| 2006 | Geoffrey Hinton | Deep Belief Networks | It is based on the stack of RBM and is used to generate more accurate results. |
| 2006 | Guang-Bin and Qin-Yu | Extreme Learning Machines | It has a fast and efficient learning speed and performs faster convergence with good generalization ability that is used for batch learning, sequential learning, and incremental learning |
| 2009 | Fei-Fei Li | ImageNet | It is developed to perform the classification task on images and computer vision |
| 2012 | Google Brain | AlexNet, The Cat Experiment with CNN | It is used to detect objects in computer vision areas. |
| 2014 | Ian Goodfellow | Generative Adversarial Neural Network | It is used for data augmentation and image improvement tasks |
| 2014 | DeepFace | It is a facial recognition system used to identify human faces | |
| 2016 | DeepMind | AlphaGo | It is made up of CNN which is used to learn and understand anything and accomplish the task in a shorter time than humans |
Complex optimization problems [21], such as designing topology, tuning and learning hyperparameters, can be solved efficiently using deep learning optimization with bio-inspired algorithms. Diagnosing diseases from many patients through the data collected with a different category of a specific disease is a classification problem. Robust, precise, and quick cardiac disease detection is crucial from a medical standpoint. Furthermore, it is a proven fact that, in comparison to ML approaches, DL-based cardiac disease identification offers generally better performance. Additionally, it has been noted that the majority of the articles have only used one dataset to evaluate the effectiveness of the various categorization methods. The conclusions drawn from the outcomes of one dataset might not apply to other datasets. As a result, it is necessary to test and assess the performance using at least two or more common datasets. For the Cardiac disease classification type, the data will be big, so with the support of deep learning methods embedded with bio-inspired algorithms, it will be able to classify it more accurately in diagnosing. Most of the early machine learning techniques predict various diseases type with accuracy suitable for small datasets [22]; for large datasets, deep learning optimization with a bio-inspired algorithm can predict it with more accuracy, which leads to the idea of embedding deep learning with bio-inspired algorithms for cardiac disease classification. Additionally, it has been noted that the ensemble version [23] of the top-performing model shows superior detection performance to other models. This motivates us to survey bio-inspired optimization algorithms with deep learning models for the classification of cardiac disease.
This paper mainly focused on research in cardiac disease with state-of-the-art deep learning models embedded with bio-inspired algorithms. The remainder of this paper is organized as follows: In section 2, elaborate information on cardiac disease is presented with deep learning methodologies performance in the prediction process. In Section 3, the related work about the various deep learning models with applications is listed. In Section 4, different datasets used by various researchers in different countries have been listed. In Section 5, deep learning benefits with embed on bio-inspired algorithms were listed for facing challenges in designing and training the deep networks for producing higher accuracy. In Section 6, the challenges of deep learning with bio-inspired algorithms and its future work are explained. Finally, in Section 7, the conclusion of the deep learning survey together with immanent trends that might be enhanced in the future, guide research towards health sectors in disease classification.
2. CARDIAC DISEASE: RESEARCH PROSPECT
Cardiac disease [24] has been a leading cause of death for over three decades. Approximately 18 million individuals drowned from Cardio Vascular Diseases [25] in 2019, depicting 30% in the world. Of these passing, 85% are because of heart failure and stroke. Most cardiovascular diseases can be abstained from pointing to the behavioral risk factors [26] of mankind, such as smoking, an unhygienic diet that leads to fatness, physical idleness, and the critical use of liquor. People with cardiac disease or who are at serious cardiovascular risk need a prior diagnosis and handle it through therapy and medications.
The side effects of cardiac disease [27] incorporate windedness, the shortcoming of the actual body, swollen feet, and exhaustion with linked signs, for instance, raised jugular venous pressing factor and fringe distension affected by practical cardiovascular or absence of cardiac irregularities. The examination strategies in the beginning phases used to distinguish Cardiac illness were confounded, and its subsequent intricacy is the significant cause that influences the norm of life. Cardiac disease determination and doctoring [28] are mind-boggling, particularly in non-industrial nations, because of the uncommon accessibility of symptomatic mechanical assembly and the lack of doctors and other assets which influence legitimate expectations and hospitalization of Cardiac patients. The precise and legitimate conclusion of cardiac disease trouble in patients is vital for diminishing their related chance of serious Cardiac complications and improving the protection of the heart. For this kind of challenge, deep learning models [29] can provide the best accuracy in detecting it priorly.
Nowadays, the health-related issue is a disaster for all human beings. Predicting, analyzing, and treatment purposes need so much cost, as well as for data handling process, is difficult. Since it creates a maximum portion of the information that medicos are incapable to deduce and use expertly, so Deep learning [30] has transpired as a more errorless and potent model in a voluminous kind of medical obstacles such as prognosis, prophecy, and invasion. Deep learning methods play a key role in classifying cardiac disease [31], which is a leading cause of death globally that can also be described in many ways by the researchers, such as coronary artery disease, cardiovascular disease, congenital heart disease, cardiomyopathy, and myocardial infarction.
To solve the complication of cardiac disease, various researchers developed machine learning and deep learning-based models that can be widely used in the prediction and diagnosis process. Latha C et al . [32] proposed ensemble classification techniques such as Naïve Bayes, Random forest and obtained an accuracy of 83.1%. Gong J et al . [33] used the Recurrent Attention Model for the prognosis of heart disease with an accuracy of 93.4%. Shiny Irene D et al . proposed Deep Belief Network and Extreme Learning Machine for heart disease prediction using hybrid fuzzy k-methods and achieved an accuracy of 97.62%. Garate Escamila et al . [22] used feature selection and principal component analysis and produced an accuracy of 98.7% for predicting heart disease. Beunza J et al . [34] proposed several machine learning models, such as decision trees, random forests, support vector machines, and neural networks, and classified them with an accuracy of 85%. The datasets used by the various researchers for the prediction of cardiac disease are from UCI Machine Learning Repository, Heart (Hungary), Heart (Swiss), Heart (Cleveland), CAD-Based Datasets, Statlog Heart Disease, Parkinson’s Disease (PD), Framingham Heart Study, and Clinical Data of Shanxi Academy of Medical Sciences. The various researchers utilized popular datasets for cardiac disease prediction and detection with several deep learning models with accuracy are listed in Table 2.
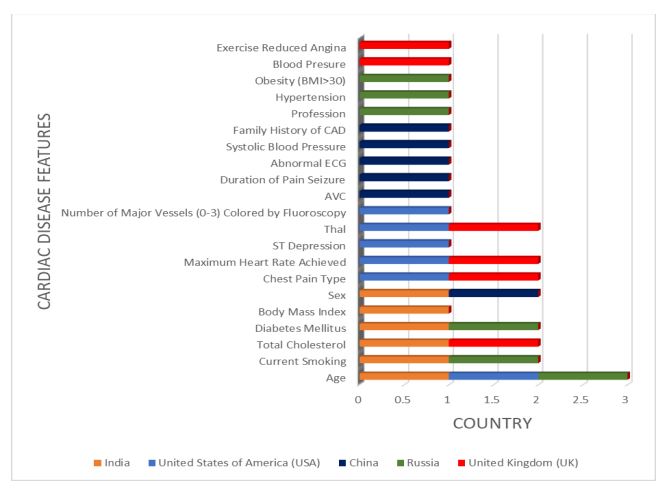
The important features used by the researchers of five different countries for the analysis of cardiac disease detection are shown in Fig. (1).
| Author Name | Year | Models | Dataset | Accuracy |
|---|---|---|---|---|
| Dutta A, M et al . [35] | 2020 | Neural Network with Convolutional Layers | National Health and Nutritional Examination Survey (C) | 79.5% |
| Makhadmeh Z, Tolba A [36] | 2019 | Higher-Order Boltzmann Deep Belief Neural Network (HOBDBNN) | UCI Machine Learning Repository | 99.03% |
| Mohan S et al . [37] | 2019 | Hybrid Random Forest with A Linear Model (HRFLM) | Cleveland Dataset | 88.7% |
| Vivekanandan T, Sriman Narayana Iyengar N [38] | 2017 | Feature Selection, Differential Evolution (DE) Algorithm, Fuzzy AHP, and A Feed-Forward Neural Network | Cleveland Heart Disease Dataset From UCI | 83% |
| Amin Ul Haq et al . [39] |
2018 | K-NN, ANN, SVM, DT, and NB | Cleveland Heart Disease Dataset 2016 | 83% - 89% |
| Mufudza C, Erol H [40] |
2016 | Poisson Mixture Regression Model | Cleveland Clinic Foundation Heart Disease Data Set | 86.7% |
| Dwivedi A [41] | 2018 | Artificial Neural Network (ANN), Support Vector Machine (SVM), Logistic Regression, K-Nearest Neighbor (KNN), Classification Tree and Naïve Bayes | Statlog Heart Disease Dataset | 85% |
| Orphanou K et al . [42] |
2015 | Extended Dynamic Bayesian Network (DBN) Model | Stulong | 85.5% |
| Tay D, Poh C, Van Reeth E et al . [43] | 2015 | Support Vector Machine (SVM) | Cardiovascular Health Study (CHS) Dataset | 95.3%, 84.8%, and 90.1% |
| Henriques J, et al . [44] |
2015 | Trend Analysis of Telemonitoring Data | Historical Dataset - Myheart Telemonitoring Study | 78% and 80% |
| Javeed A, Zhou S, Yongjian L et al . [45] |
2019 | Random Search Algorithm (RSA), Random Forest Model, Grid Search Algorithm, | Cleveland Dataset |
93.33% |
| Dogan M, Grumbach I, Michaelson J et al . [46] |
2018 | Random Forest Classification Model for Symptomatic CHD And Integrated Genetic-Epigenetic Algorithms | Framingham Heart Study | 78% |
| Vankara J, Lavanya Devi G [47] | 2020 | Ensemble Learning by Cuckoo Search | UCI | 83%-86% |
It is shown in Fig. (1). five different countries, such as India, the United States of America (USA), Russia, China, and the United Kingdom (UK), are the major 6 features they used for cardiac disease detection by Deep learning models.
3. DEEP LEARNING MODELS
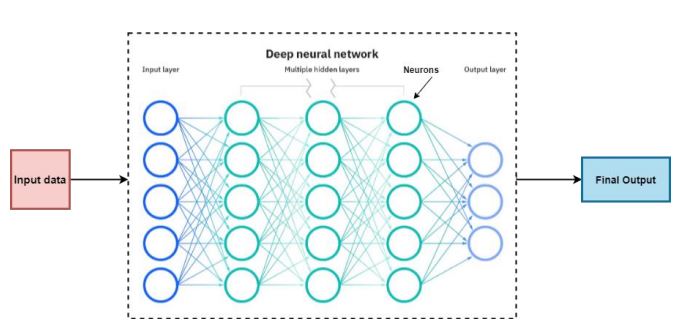
Deep learning [48] is a subfield of machine learning technique that teaches you not just the relationship between two or more variables, but also the rules that govern that relationship as well as the logic behind it. The goal of deep learning [49] is to create higher-level information from lower-level information by learning the knowledge chunk at several levels of representation and abstraction. The deep learning concept was initiated from an analysis of artificial neural networks (ANNs) [50]. The word deep in deep learning refers to the number of layers through which the data is transformed to the next layer for the prediction process of the final output. The first layer of the deep learning network processes a preliminary data input and transfers it to the next layer as output. The second layer processes the previous layer’s information by enhancing additional information in a hidden way and transferring its result to the next layer. The next layer takes the second layer’s information, includes raw data of the user’s application, and makes the machine’s pattern even better. This continues across all levels of the neuron network, and finally, the output is predicted based on the given input features. Fig. (2) shows the architecture of the basic deep learning network. It first learns the primitive features followed by high-level features that help the building model so efficiently.
In this section, the various deep learning models, such as deep neural networks, convolutional neural networks, recurrent neural networks, extreme learning machines, deep belief networks, and transfer learning, are explained with their recent trends.
3.1. Deep Neural Network
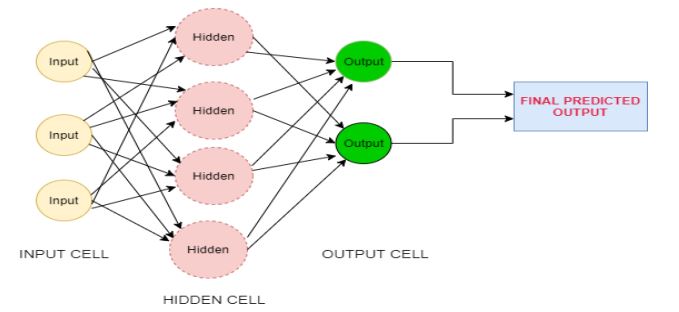
Deep Neural Network [51] history was first initiated in year 1943 by Warren McCulloch and Walter Pitts that is dependent on the neural organizations of the human mind. Neural Networks can learn without help from anyone else and produce a yield that isn't restricted to the information given to them. The information is put away in its organizations rather than a data set, consequently, the deficiency of information doesn't influence its working. Deeper networks are efficient in terms of computation and the number of parameters. A neural network with some level of unpredictability, normally in two layers, qualifies as a deep neural network (DNN), or a deep net for short. Deep nets measure information in complex ways by utilizing refined mathematical modeling. The architecture of the deep neural network is shown in Fig. (3).
3.1.1. Advantages
1. It can learn by itself and produce an output that is not limited to the input provided to them.
2. The input is stored in its networks instead of a database and so the loss of data does not affect its working performance.
3. They can perform multiple tasks in parallel without affecting the system's performance.
3.2. Convolutional Neural Networks
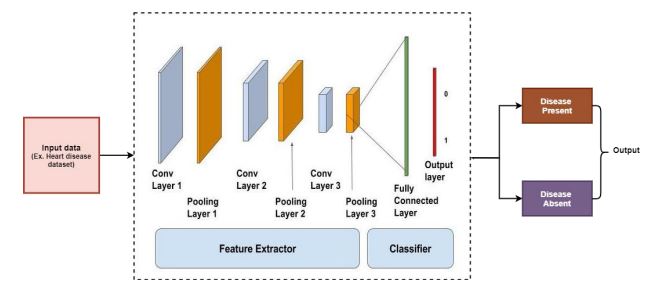
Convolutional neural networks were first introduced by Yann LeCun [52] in the year 1980. It is a type of neural network with one or more convolutional layers. It can automatically detect important features without the support of humans and is efficient in the computation process. It is performed by the concept of neurons that attain data from only a limited subdomain of the previous layer. CNN is used in the province of speech recognition and text classification for natural language processing and is used mainly for image classification problems. The architecture of the convolutional neural network is shown in Fig. (4).
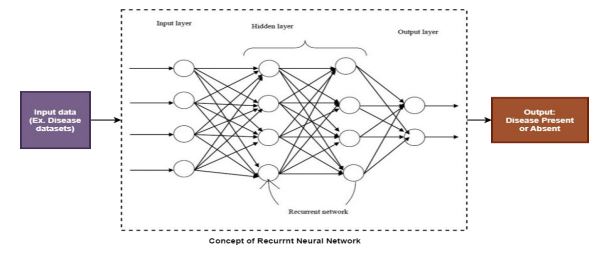
3.3. Recurrent Neural Network
A recurrent Neural Network [53] was discovered by John Hopfield in the year 1982, and it is a kind of neural network that allows previous outputs to be used as inputs for sequential data. It is one of the algorithms that seem to be advancing in the field of deep learning. It is built in the context of theoretical neuroscience. It is a very powerful and robust type of neural network. Like CNN, it is also motivated by biological examples. The architecture of the recurrent neural network is shown in Fig. (5).
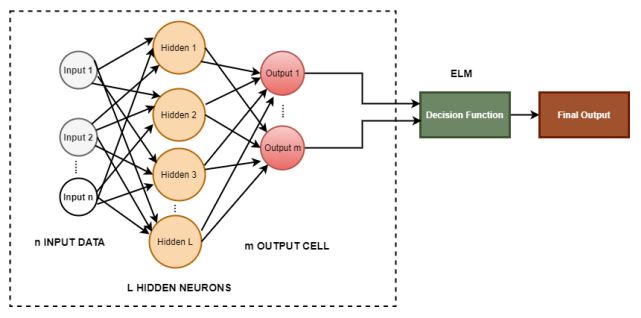
3.4. Extreme Learning Machine
ELM (Extreme Learning Machines) is a feedforward neural network that was invented by G. Huang [54] in the year 2006. ELM, as a new technique, reached out for converging, feature selection, and representational learning. ELM has effortlessness of use, snappier speed of learning, more prominent speculation execution, fittingness for a few nonlinear piece capacities, and actuation work. ELM has been applied in an assortment of spaces, for example, biomedical designing, Computer vision, framework identification, and control and mechanical technology. The architecture of the extreme learning machine is shown in Fig. (6).
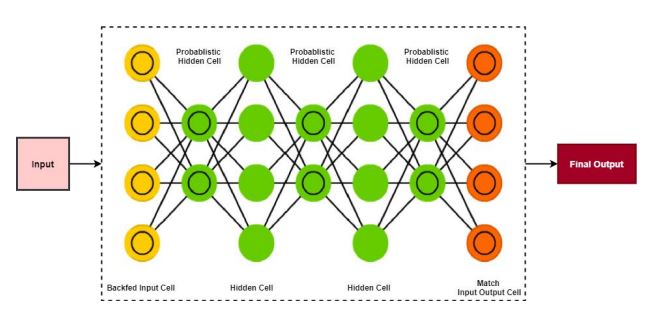
3.5. Deep Belief Network
Deep Belief Networks [55] were introduced in the year 2007 by Larochelle et al . as probabilistic generative models collected by stacked modules of Restricted Boltzmann Machines (RBMs) and provide an alternative to the discriminative nature of traditional neural nets. It can be used for identification, clustering, image processing, video sequels, signal-capture data, and also for training nonlinear autoencoders. The main characteristics of DBN are fast inference and the ability to encode higher-order network structures. The architecture of deep belief networks is shown in Fig. (7).
3.5.1. Advantages
1. It has the capability of learning features that can be done by a strategy of learning it layer-by-layer.
2. DBN can avoid the problem of overfitting and underfitting by implementing unlabelled data skillfully.
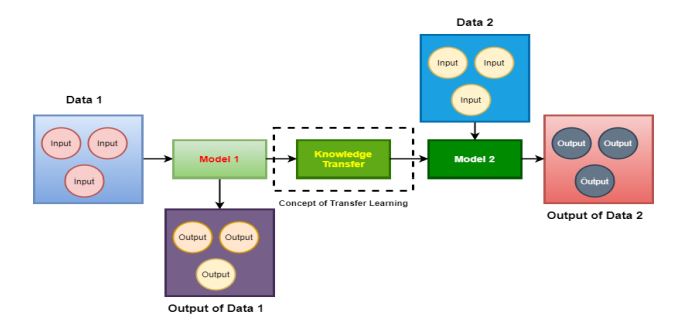
3.6. Transfer Learning
Transfer learning [56] was introduced in the year 1976 by Stevo Bozinovski and Ante Fulgosi. It is a famous methodology in deep learning where preceding models are utilized as the beginning stage of natural language processing and computer vision undertakings, given the immense register and time assets needed to create neural organization models on these issues. Transfer learning is prominent in deep learning for large datasets problems. It can be used in data-related research on image and language processing. It acts as an optimization process used to save time and result in better performance. The architecture of transfer learning is shown in Fig. (8).
| Author | Application | Method/Algorithm | Year |
|---|---|---|---|
| A. Voulodimos, N. Doulamis et al . [57] |
Computer Vision | Convolutional Neural Network | 2018 |
| M. Havaei et al . [58] | Brain Tumor Segmentation | Deep Neural Networks | 2017 |
| S. Purushotham, C. Meng [59] |
Large Healthcare Datasets | Recurrent Neural Networks | 2018 |
| Ding S et al . [60] | EEG Classification | Extreme Learning Machines | 2015 |
| Sagar G. V [61]. | Malware Detection on the Internet of Things | Deep Belief Networks | 2019 |
| Muhd Suberi A. et al . [62] | Automated Ischemic Classification in Posterior Fossa Ct Images | Transfer Learning | 2019 |
3.6.1. Advantages
1. It speeds up the task of training the model on a new task by utilizing the pre-trained model and results in a good performance.
2. It has the power to learn information from simulations.
3.6.2. Disadvantages
1. It has the problem of negative transfer, which reduces the performance of the developed new model.
2. It has an overfitting problem due to the learning capability of the model in terms of noises from training data that impact negatively the final output.
Deep learning models’ recent trends and applications are displayed in Table 3. It shows that deep learning techniques can be used by researchers for various research applications.
The developed DL models yielded the most noteworthy characterization execution for Cardiac Disease in any event when utilizing boisterous ECG signals [63]. DL models can excerpt features, consequently forgoing the need to build feature extraction algorithms. They are strong to regular varieties, able to do hugely resemble calculations, and can undoubtedly be summed up for various issues [64]. At last, they can manage large information [65] and henceforth, can be utilized in the clinical field for exact and quick diagnosis. Despite that, DL techniques are as yet in the underlying phase of advancement. More tasks to compete in the future to analyze the design with a large data collection before medical use.
4. DATASET DESCRIPTION
Table 4. concisely delivers data from the Cardiac Disease datasets [66]. The table shows the major attributes of the datasets, such as the dataset name, samples, features, and country location. The most accepted Cardiac disease-associated dataset is the Cleveland dataset. Even though the entirety of the datasets has various kinds of highlights, a few of them are generally more significant for one or the other forecast or grouping. Henceforth, the general significance of highlights for the discovery of Cardiac Disease is examined. For instance, sex and age are examined independently because the effect of these two elements is major for research objectives in most sickness states.
| Dataset Number | Dataset Name/References |
Dataset Sample Size |
Country |
Number of Features |
|---|---|---|---|---|
| 1 | Through a Questionnaire from Advanced Medical Research Institute (AMRI) hospital, Kolkata [67] | 500 | India | 24 |
| 2 | Indira Gandhi Medical College (IGMC), Shimla, India [68] | 24251 | 9 | |
| 3 | Diabetes dataset [69] | 768 | 2 | |
| 4 | ECG signals of 10 CAD patients and 10 healthy subjects at Iqraa Hospital, Calicut, Kerala, India [70] | 20 | 3 | |
| 5 | Cardiovascular heart disease dataset [71] | 500 | 13 | |
| 6 | Photoplethysmography (PPG) signals [72] | 126 | 1 | |
| 7 | Andhra Pradesh heart disease database [73] | 23 | 8 | |
| 8 | Data of 564 CAD patients [74] | 564 | 9 | |
| 9 | Data of Left ventricular ejection [75] | 93 | 1 | |
| 10 | Demographic, historical, and laboratory features [76] | 335 | 25 | |
| 11 | Dataset has 19 various attributes [77] | 214 | 15 | |
| 12 | CHD Database has samples of 70% for training and 30% for testing [78] | 750 | 7 | |
| 13 | Cleveland Dataset [79] | 303 | United States of America (USA) | 13 |
| 14 | Long Beach Dataset [80] | 200 | 13 | |
| 15 | Online dataset from the Journal of American Medical Informatics Association (JAMIA) [81] | 507 | 1 | |
| 16 | Arrhythmia database from Massachusetts Institute of Technology-Beth Israel Hospital (MIT-BIH) [82] | 48 | 5 | |
| 17 | Coronary Artery Bypass Grafting (CABG) database [2] | 13228 | 9 | |
| 18 | Data from the Department of Cedars-Sinai Medical Center, Los Angeles, California [83] | 1181 | 9 | |
| 19 | ECG data in the PhysioNet database [84] | 47 | 1 | |
| 20 | ECG Dataset [85] | 754 | 10 | |
| 21 | PREDICTION study of 39-center from July 2007 to April 2009 [86] | 1161 | 11 | |
| 22 | Cardiac Database [87] | 480 | 1 | |
| 23 | Patients with suspected CAD [88] | 10030 | 11 | |
| 24 | Diastolic heart sounds data [89] | 100 | 1 | |
| 25 | Continuous ECG signals [90] | 700 | 1 | |
| 26 | Clinical Narratives [91] | 296 | 1 | |
| 27 | Dataset has arterial narrowing (stenosis) [92] | 655 | 25 | |
| 28 | PolySearch and CAD Gene Database [93] | 128 | China | 5 |
| 29 | Data by an experimental process at Zhejiang Medical University [94] | 60 | 4 | |
| 30 | Data from Shanghai University of Traditional Chinese Medicine [95] |
551 | 51 | |
| 31 | Angina patient's participation data study [96] | 551 | 19 | |
| 32 | Arrhythmia Database from St. Petersburg Institute of Cardiological Technics [97] | 207 | Russia | 15 |
| 33 | Hospitalized in Central Clinical Hospital [98] | 487 | 16 | |
| 34 | Fantasia database [99] | 47 | 1 | |
| 35 | Statlog (Heart) dataset [100] | 270 | UK | 13 |
First, it is well-accepted and not at all surprising that a higher level of age is associated with a greater chance of developing a cardiac illness, and this risk increases indirectly through time. Men experience the expansion in riskiness at a more youthful age, while pre-menopausal ladies are observed by physical changes, and just encounter the expansion in torment at the last stage. ECG data has an important role in cardiac disease classification. The most widely used tool is Electrocardiogram [101] which is mainly utilized for clinical diagnosis in cardiac disease identification. With this ECG classification, the major problem that can be identified, such as heartbeat segmentation, cardiac arrhythmia, and heart rhythms, will be detected or predicted with the support of artificial intelligence, machine learning, and deep learning models. The types of cardiovascular disease are hypertensive heart disease, rheumatic heart disease, valvular heart disease, cardiomyopathy, aortic aneurysms, heart arrhythmia, carditis, congenital, myocardial infarction, and heart failure. For patients with heart illnesses, an assortment of cardiovascular irregularities might happen, and these anomalies ordinarily lead to changes in ECG designs. Electrocardiography is the most well-known method for observing heart movement. Different heart problems can be distinguished by the examination of ECG signal anomalies. AI-enhanced ECG-based cardiovascular disease detection is explained in this [102] work that guides researchers to decide on clinical data limitations with the patients affected with cardiac disease. To enhance or boost the permanent accurate prediction value of cardiac disease for a large amount of data or features, the Bio-Inspired algorithm can be embedded with deep learning models.
5. DEEP LEARNING EMBEDDED WITH BIO-INSPIRED
A deep learning approach can be embedded with bio-inspired algorithms for the optimization process to enhance the accuracy of the predicted value. Before going to the depth of it, let’s start by defining the concept or idea behind bio-inspired computing or algorithm. Bio-inspired computing is a pivotal subgroup of natural reckoning. Bio-inspired computing (BIC) [103] spotlights the cabals and progress of computer algorithms and prototypes based on the biological armature and living phantasm. Bio-inspired computing [104] is a realm of study with biologically enthused quantifying and entreats to solve computer science challenges using biological instances. In general, it briefs social habits and emanation, but in the computer science field, bio-inspired computing revolutionizes with artificial intelligence and machine learning. Several areas of study in biologically inspired computing, with their biological counterparts, are Genetic algorithm with evolution, cellular automata with life, emanation with ants, bees, etc., neural networks with the brain, artificial experience with animation, the artificial immune system with the immune system, and learning classifier systems with cognition and evolution. Bio-inspired computing is a significant subsection of natural reckoning or nature-enthused algorithms. Plenty of real-world problems were solved by deploying nature-enthused algorithms which embrace concepts such as reproduction peripheral structures, shaggy systems, revolutionary assessing, and swarm cognizance [105].
Bio-Inspired computing [106] is divergent from conventional artificial intelligence by its framework to digital learning. Conventional artificial intelligence uses a creationist method, while bio-inspired computing uses an evolutionary approach. Bio-inspired computing [107] starts with a comprise of basic dictums, and creatures obey those commandments. Several times, these creatures have grown within simple impediments. This approach could be considered decentralized or bottom-up. Intelligence is constantly programmed with a programmer as a creator, which sometimes makes something unknowingly with the information in traditional computing. The two leading methods in BIAs include evolutionary algorithms [108] and swarm-based algorithms, which are accomplished by the adaptation of the natural and overall behavior of creatures accordingly. But still, based on the area of inspiration from nature to enhance a vaster view over the domain, it can be further refined to differentiate the accuracy of the algorithm. The taxonomy of bio-inspired optimization algorithms is shown in Fig. (9).
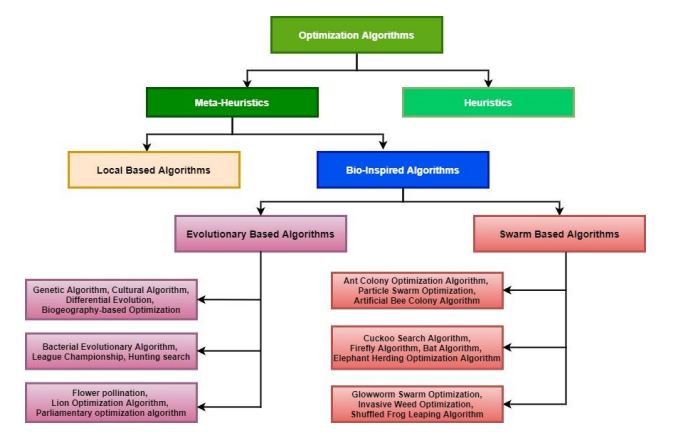
This section deals with twenty Bio-Inspired algorithms, namely, genetic algorithm, differential evolution, biogeography-based optimization, etc., from Evolutionary Algorithms (EAs) and ant colony optimization, particle swarm optimization, artificial bee colony, firefly algorithm, etc., from Swarm-based optimization algorithms.
Evolution's general meaning explains the method by which different categories of living organisms are reported to have developed from earlier forms during the history of the earth. So, the Evolutionary algorithm can be defined as a subset of its computation, which uses a framework inspired by biological evolution, for example, in the field of reproduction, mutation, recombination, and selection. It is based on a heuristics approach that can able to solve the problems that cannot be solved by polynomial time, such as the NP-hard problem. EA contains some steps such as initialization, evaluation, selection, reproduction, cross-over, and mutation. The steps shown above can provide an easy way to modularize the implementations of this algorithm category.
The notions of nature and biological activities have motivated the burgeoning of many enlightened algorithms for problem-solving. The problem-solving feature of artificial evolution is built into the selection process, which consists of two basic steps. 1) an evaluation of the phenotype that provides a quantitative score, also known as fitness value, and 2) a reproduction operator that makes a large number of copies of genotypes corresponding to phenotypes with high fitness values. These algorithms are commonly classified as evolutionary computation and swarm intelligence (SI) algorithms. Evolutionary computation is an idiom used to embellish algorithms that were enthused by the essence of the fittest. Swarm intelligence is an idiom used to embellish algorithms for disseminated problem-solvers that were enthused by the concerted team intellect of swarm or collective habits of bug enclaves and other species inhabitants.
Evolutionary algorithms are successfully applied to a lot of numerous problems from different areas or domains, including optimization, machine learning, research on operations, automatic programming, computational biology, and community structure. In a collection of distinct effects, the numerical function, which exhibits several problems, is not recognized, and the ideas at specific bounds are acquired by the method of replicas. Compared to other optimization strategies, an essential benefit of evolutionary algorithms is that they can cover multi-forming functions. Some of the benefits are enumerated as follows: It is notionally facile, flexible, and neutral in disparity with other numerical tactics. Invariance and evolutionary algorithms are worn to attune many results in modifying circumstances and environments. It can domicile challenges without support from human experts. EA has some disadvantages also: No assured optimized solution for some specific finite time. It delivers beneath a weak hypothetical basis concept. It uses parameter tuning. The cost of computation is prohibitive.
Swarm intelligence (SI) is a section of computational insight that discusses the conjunct habits emerging within an ascetic-organizing society of agents. Swarm Intelligence has absorbed the attention of reams of researchers on diverse concerns. Bonabeau cleared SI as “The embryonic collated sapience of clumps of facile envoys”. SI is the collaborative insight habits of ascetic-perspective and disseminated ways, e.g., mimicking teams of facile legates. Some instances of swarm-based intelligence are team hunting of communal pests, collaborative expedition, den structure of communal pests, communal grouping, and converging.
5.1. Genetic Algorithm
A genetic algorithm [109] is defined as a search pragmatic that is enthused by Charles Darwin's notion of standard evolution. This procedure depicts the routine of wanted preference with reproduction to produce offspring of the next generation by selecting the fittest individuals. The genetic algorithm [110] was proposed by Holland in 1975 and defined as an evolutionary-based stochastic optimization algorithm with the potential for universal search. GAs is one of the most eminent classes of algorithms under EAs, which are roused by the evolutionary algorithm concepts in bio-inspired. It is commonly used in the applications of neural networks, particularly in recurrent neural networks, distributed computer network topologies, rule set prediction, feature selection for machine learning, and clinical decision support in ophthalmology.
| Algorithm 1: Genetic Algorithm |
|---|
| Steps: A1. Originate a random populace of n(i) gene A2. Estimate the fitness f(x) value of each gene x(j) in the populace A3. Construct a recent populace by iterating the succeeding steps until the new populace is finished i. Choose two parent genes from a populace conferring their fitness value. ii. The boundary probability traverse over the parents to construct a new progeny (children). If no boundary was per- formed, the progeny is an accurate sample of parents. iii. Transformation probability evolves new progeny at each spot (locale in gene). iv. Locus recent progeny in the latest populace A4. Utilize freshly created populace for an additional execution of the algorithm A5. If the termination criteria are satisfied, abort, and revert the finest result in the present populace, else A6. Go to step 2 |
5.2. Cultural Algorithms
Cultural algorithms (CA) [111] is one of the population-based algorithms with a division of evolutionary computation where there is an intelligence model called the hypothesis way. A cultural algorithm is an elongation of a conventional genetic algorithm. Cultural Algorithms were proposed by Robert Reynolds in the year 1994 and are characterized by pith an outlet of evolutionary computation that benefits a mechanism of knowledge entitled hypothesis capacity. The cultural algorithms are also reasoned as an elongation of hereditary procedures. Culture is precise as a scheme of cuneiform arcane notional phantasm that is predominantly and politically forwarded surrounded by commodities. It is primarily utilized in the applications of various optimization problems, social simulation, and real parameter optimization.
5.3. Differential Evolution
In bio-inspired algorithms, the most famous of these algorithms, Differential Evolution (DE) [112], is recommended by Storn and Kennedy numeral optimization problems-based population of the algorithm by using evolutionary operators, selection, crossover, and mutation. Differential Evolution (DE) is one of the population-based stochastic methods for global optimization introduced to the public in the year 1995. During the last 20 years, an inquest on Differential Evolution has secured a powerful fettle, yet there is still a new application area emerging. It is commonly considered a reliable, robust, accurate, and rapid optimization technique. It is vastly inclined in the applications of numerical optimization, applied science, parallel computing, multi-objective optimization, and constrained optimization.
| Algorithm 2: Cultural Algorithm |
|---|
| Steps: A1. Start the process A2. t[i]=0; A3. Load the populace POP (0); A4. Load the notion connect NC (0); A5. Load the contact gutter CG (0); A6. Estimate (POP (0)); A7. t[i]=1; A8. repeat A9. Contact (POP (0), NC(t[i])); A10. Arrange (NC(t[i])); A11. Contact (NC(t[i]), POP(t[i])); A12. Regulate the fitness value (NC(t[i]), POP(t[i])); A13. t[i] = t[i]+1; A14. Choose POP(t[i]) from POP(t[i]-1); A15. Expand (POP(t[i])); A16. Estimate (POP(t[i])); A17. until (executing condition satisfied) A18. Stop the process |
| Algorithm 3: Differential Evolution |
|---|
| Steps: A1. Initialization process started Parameter boundaries should be defined If not, parameter extents should cover the suspected optimum A2. Two arrays are used, which represent the current and the next generation Display the number of solutions for each generation Read the real-valued vectors of parameters Evaluate the fitness or cost of each vector of parameter A3. Create the challenger by mutation and recombination A4. Mutating with vector differentials to make noisy random vector |
5.4. Biogeography-based Optimization
Biogeography-based optimization (BBO) [113] is a historic populace-based evolutionary algorithm (EA) that optimizes a function by speculatively and constantly increasing the candidate solutions about a given dimension of quality or fitness function. Biogeography is based on the biogeography concept. BBO can be used on discontinuous functions with the ideas of the migration strategy for solving optimization problems. For example, flexible job scheduling is explained by the BBO algorithm. It is vastly inclined in the applications of computational intelligence, the field of transportation, image processing, and bioinformatics.
5.5. Bacterial Evolutionary Algorithm
Bacterial Evolutionary Algorithm (BEA) [114] is one of the population-algorithm based on the Pseudo-Bacterial Genetic Algorithm (PBGA) supported by a novel genetic operation called the gene transfer operation. This new operation develops relationships among the individuals of the population. Bacterial EA is inspired by the biological phenomenon of microbial evolution, which was in turn, enthused by the evolutionary mechanisms of bacteria, which has shown a terrific enhancement in the local improvement of chromosomes rather than other EAs. It is used for rapid adaptation in an ever-changing environment and is also used in fuzzy system design. It also automatically performs data clustering concepts. It is widely utilized in the applications of automatic data clustering, fuzzy system design, and pattern recognition.
| Algorithm 4: Biogeography-Based Optimization |
|---|
| Steps: A1. Start the process A2. Describe problem A3. Generate initial solutions A4. Set the number of parameters, such as no. of islands, etc., A5. Test the number of generations, if true, obtain the best solution, then end the process, else A6. Arrange the solutions in ascending order A7. Assign the number of species for each solution based on the order A8. Test the number of islands, if true, apply mutation inverse proportional with each solution and go to step 5, else check each solution to be modified based on the set parameters |
| Algorithm 5: Bacterial Evolutionary Algorithm |
|---|
| Steps: A1. Start the process A2. Initialization beginsa A3. Gene transfer completes A4. Bacterial mutations A5. Check the termination condition, true means end the process A6. Else repeat step 2 |
5.6. League Championship Algorithm
League Championship Algorithm (LCA) [115] is an exceptional modern chaotic population-based algorithm with global optimization that ventures to disciple an entitlement mold wherein spurious teams play in an artificial game for many weeks in an iterative manner. The League schedule is planned according to the availability of the teams, and the game is conducted every week; teams play in pairs, and the result is approved in terms of win or loss. The team’s playing brawniness is calculated as fitness value, and a solution is found by the conclusion of a certain team. It is particularly used in the applications of real-time task scheduling, business, industry, and engineering.
| Algorithm 6: League Championship Algorithm |
|---|
| Steps: A1. Start the process A2. Initialize the control parameters A3. Create initial teams’ formation randomly and determine the team’s strength A4. Generate the league schedule A5. Determine the loser or winner for each match based on strengths A6. Based upon the condition, checking the capability and the result is true means, finish it, else A7. Set up the team formation once again based on the previous result and form the best team, then go to step 5 |
5.7. Hunting Search
Hunting Search [116] is a significant populace-based algorithm used for solving elongated optimization problems. It is a meta-heuristic in nature that utilizes the mechanisms of a bunch of venery of certain creatures, such as dolphins. The hunting pool is demonstrated by a collection of conclusions where every hunter is characterized by one of these results. The coaction of the comrades of the cluster called hunters guides them to girdle a prey and trap it, identical to the optimization methods which conclude in attaining a global solution as bound by an objective function. The model used here for bunch hunting of animals is done by locating for food, such as how wolves hunt. It is widely utilized in the applications of job selection, optimization of steel cellular beams, and traveling salesman problem.
| Algorithm 7: Hunting Search Algorithm |
|---|
| Steps: A1. Start the process and set the parameters A2. Declare and set the Hunting Group (HG) A3. Form a loop of NE[i] iterations A4. Form a loop of IE[j] iterations A5. Forward it towards the captain A6. Formulate the positions A7. If the distance from the best to the worst hunter<EPS[k] A8. Quit the loop iterations of IE[j] to the reformation A9. End if A10. End loop iterations of IE[j] A11. Reformation of hunter’s process done A12. End loop iteration of NE[i] |
5.8. Flower Pollination Algorithm
The flower pollination algorithm (FPA) [117] is a memorable populace-based nature-enthused algorithm that mimics the fertilization habits of flowering plants. The optimal plant replication methodology comprises the essence of strength in provisos of values. The flower pollination algorithm (FPA) is a recently developed optimization strategy resulting from the breeding habit of flowers. The performance in FPA optimization is enhanced by strengthening the orthogonal learning (OL) policy which copies the orthogonal experiment design (OED). The mechanisms of FPA analyze relevant, valuable data and maintain commanding population diversity. It is particularly used in the applications of computational intelligence, structural mechanics, transportation problems, wireless sensor network, and distributed systems.
| Algorithm 8: Flower Pollination Algorithm |
|---|
| Steps: A1. Start the process A2. Initialization of parameters FPA, size, number of iterations, and the amount is done A3. Construct the populace with a random solution A4. Calculate the unbiased function from a chaotic solution and choose the finest solution from the present populace A5. For every repetition A6. If chao[i]>amount[j] is true, then A7. Do global pollination using levy distribution and form a new populace A8. Else, Do local populace A9. After the completion of the above operation, now evaluate the objective function corresponding to the new solution A10. Store and notify the best current solution A11. If the utmost numeric of repeated operations is satisfied, then A12. Display the best solution and end the process, else A13. Increment the value by one and go to step 5 |
5.9. Lion Optimization Algorithm
Lion Optimization [118] is meticulous populace-based meta-heuristic algorithms utilize to perform a random operation for producing the populace over the resulting space. The main operator of LOA is mating which specifies extending new solutions, sectional defense, and sectional takeover. It has some marvelous styles in snatching prey, sectional marking, and migration, which differ from resident lions. It has interesting social behavior, termed pride, which is why it is called a king of the forest. It focuses on strengthening their species at every generation's time. The dominating lion is often called a territorial lion which fights with other defense lions and maintains its spot all the time. It is broadly exploited in the applications of renewable distributed generations, annual electricity consumption forecasting, feature selection problem, and various engineering problems.
| Algorithm 9: Lion Optimization Algorithm |
|---|
| Steps: A1. Start the process and initialize the parameters Xmale[i], Xfemale[j] and Xnomad1[k] A2. Evaluate the parameters by f(Xmale[i]), f(Xfemale[j]) and f(Xnomad1[k]) A3. Initialize the new parameter by setting fref[x[=f(Xmale[i]) and Ng[y]=0 A4. Update and notify the values of Xmale[i] and f(Xmale[i]) A5. Execute the fertility calculation A6. Do the mating process and procure the cub pool A7. Execute gender clustering and attain the values of Xm_cub[i] and Xf_cub[j] A8. Set Acub[i] as zero A9. Perform the growth function of the cub A10. Execute the sectional defense; if the defense output is 0, go to step 4 A11. If Acub[i]<Amax[j], go to step 9 A12. Execute the sectional takeover and procure the altered value of Xmale[i] and Xfemale[j] A13. Enhance Ng[y] by one A14. If the execution criteria are not met, go to step 4, otherwise, abort the process. |
5.10. Parliamentary Optimization Algorithm
Parliamentary optimization [119] is one of the population-based stochastic optimization algorithms. A parliamentary system's working process starts with a network of government in which the parliament holds power to rule and execute the laws. The procedure followed for electing members of the parliament is processed by conducting general elections. People usually vote for the experienced parties available in the country rather than choosing particular persons with their abilities. Members of a parliament maximally belong to political parties. They support, by default, their party members in parliamentary votes. There are two procedures in parliamentary elections: the majority election method and the equivalent demonstration. It is particularly used in the applications of community detection in social networks, Web page classification, automatic mining of numerical classification, manufacturing, and scheduling.
5.11. Ant Colony Optimization
Ant colony optimization [120] is considered the population-based algorithms inspired by the proficiency of monitoring and synchronization with searching for solutions for domestic problems. Stigmergy theory was invented by Pierre-Paul Grasse in 1959 and described the behavior of building a nest. The ant system was introduced by M. Dorigo in the year 1991 in his doctoral thesis and published in the year 1997 as the ant colony system (ACS). Naturally, ants are blind and small in size, with the advantage of finding the shortest route to their food. Antenna and pheromones are used with touch together. The term “ant colony” points to the group of the workforce, generative individuals, and ponders that live together, collaborate, and handles one another non-aggressively. It is generally used in the applications of scheduling problems, vehicle routing problems, assignment problems, set problems, device sizing problems in nanoelectronics physical design, antenna optimization and synthesis, and Image processing.
| Algorithm 10: Parliamentary Optimization Algorithm |
|---|
| Steps: A1. Start the process by initializing the populace Splitting the populace into N[i] groups of L[j] membered Select the most suitable individuals as contenders A2. For every group of people A3. Recurrent the steps by two types of competition Internal work: Favor common members towards contenders Reselect the fitted contenders Calculate the strength of each team External work: Unite the powerful teams with probability pm[x] Clear powerless teams with probability pd[y] A4. Do until (termination criteria are satisfied) A5. Display the finest candidate |
| Algorithm 11: Ant Colony Optimization |
|---|
| Steps: A1. Set parameters, and initialize pheromone trails A2. SCHEDULE_ACTIVITIES A3. Construct Ant Solutions A4. Daemon Actions {optional} A5. Update Pheromones A6. END_SCHEDULE_ACTIVITIES |
5.12. Particle Swarm Optimization
Particle swarm optimization (PSO) [121] is a conventional populace-based global optimization strategy with a computational knowledge-oriented and stochastic. It is enchanted with the communal habits of bird flocking and its method of piercing for grub. In many fields of engineering optimization areas, the PSO has been extensively applied owing to its exceptional searching, computational efficiency, effortless concept, and simple implementation. PSO algorithm was developed by Kennedy and Eberhart in the year 1995, also dependent on a meta-heuristic swarm-based that models the social behavior of fish schooling or bird flocking. It is particularly used in the applications of healthcare in diagnosing, telecommunications, control, data mining, design, combinatorial optimization, power systems, and signal processing.
5.13. Artificial Bee Colony
The artificial Bee Colony (ABC) [122] algorithm bestowed and developed by Karaboga in the year 2005 emulates the foraging behavior of honey bees, and it is applied to many problems faced in various research areas. ABC is categorized into two types: mating behavior and foraging behavior. ABC is one of the population-based search strategies with an optimization tool in which the artificial bees modify individuals called food positions with juncture, and the bee's objective is to detect the spots of the grub source with the highest moisture quantity. The ABC has high flexibility, which allows adjustments and the ability to handle the actual cost. It is particularly used in the applications of cluster analysis, constrained optimization problems, structural optimization, advisory system, software testing, numerical assignment problem, face poses estimation, bioinformatics field, and wireless sensors.
| Algorithm 12: Particle Swarm Optimization |
|---|
| Steps: A1. Start the process by initializing each particle END A2. Do A3. Evaluate the fitness value of each particle A4. Compare the fitness value with the other enhanced fitness value (afinest[i]) from storage A5. Emplace present value as the recent pBest[i] stop A6. Select the particle with the enhanced fitness value from the old particles as the bfinest[j] A7. For every particle A8. Evaluate the velocity of the particles (a) Notify and save the particle location value (b) stop A9. While utmost replications or fewest lapse principles are unlike those obtained |
| Algorithm 13: Artificial Bee Colony |
|---|
| Steps: A1. Starting the food sources for all employed bees A2. ITERATE A3. Every chosen bee looks for grub origin by thinking from storage and confirms the closest origin, then calculates its moisture quantity and matinees in the comb A4. Every observer looks at the matinees of chosen bees, selects a single origin based on the matinees, and then forwards to that origin. Then select an intimate, with calculating its moisture quantity. A5. Restricted grub origins are persistent, then it was changed with the recent grub origins found by spies. A6. The finest grub origin is discovered and stored. A7. UNTIL (conditions are true) |
5.14. Cuckoo Search Algorithm
Cuckoo search [123] is an important population-based optimization algorithm enhanced by Xin-she Yang et al ., in the year 2009. The working principle of it is to smear their ova in the shelters of different feeding birds. Cuckoo search is inspired by the help of breeding behavior and is also applied to several optimization challenges. From the nature-inspired area, a Cuckoo search is also one, which is used mainly to solve several optimization problems in different domains of engineering. It can able to maintain the balance between local and global random walks in solving global optimization using the switching parameter. Due to less research on the switching parameter, it was fixed at 25%, so the impact of dynamic in nature was not able to be assessed by the method. It is broadly exploited in the applications of speech reorganization, job scheduling, Neural Computing, and global optimization.
5.15. Firefly Algorithm
The firefly algorithm (FA) [124] is an exhaustive populace-based algorithm developed by Yang in the year 2007 based on the transmission and fireflies' flashing behavior. It is prudent as a unique swarm-based heuristic algorithm for reserved optimization work enthused by the flashing behavior of fireflies. The algorithm incorporates a population-based continual operation with uncountable agents simultaneously solving measured optimization challenges. Agents convey with each other via bioluminescent glowing that provides them to examine the cost function space more expertly than in a standard distributed random search. It is generally used in the applications of machine learning, revolutionizing computer programming, economics, computational intelligence, and decision science.
| Algorithm 14: Cuckoo Search Algorithm |
|---|
| Steps: A1. Start the process A2. Initialize the random populace A3. Obtain a cuckoo unevenly by heavy-tailed A4. Calculate the value of fitness A5. Choose the shelter or nest amidst unevenly A6. If Fitness is less than the nest solution, then A7. Replace it with another best solution else A8. Use the nest as the solution A9. For both steps, 7 and 8, then perform abandon a fraction worst nest and create a new nest by heavy-tailed A10. Store the current best solution A11. If no. of the nest is less than or equal to maximum iterations, then find the best nest, else go to step 3 A12. End the process |
| Algorithm 15: Firefly Algorithm |
|---|
| Steps: A1. Start the process A2. Define constraints and initialize the populace, and parameters of fireflies A3. Evaluate the fitness rate of every firefly A4. Update the dazzle potency of it by the objective function A5. Realize the movements by the attractiveness of the parameters A6. Arrange the positions of the fireflies and get the best one A7. Check the stopping criteria condition, if true, then return the solution and end the process, else A8. Go to step 3 |
5.16. Bat Algorithm
The Bat algorithm [125] is a spesh population-based metaheuristic algorithm for global optimization. It was enthused by the echolocation habits of microbats, with erratic pulse rates of exhalation and chatter. The Bat algorithm was developed by Xin-She Yang in the year 2010. Naturally, even in darkness time, the bat can easily find their prey. Bat are enchanting animals. It is the only animal that got wings in mammas type. The advanced capability of the bat is echolocation. It is one of the promising algorithms that can be used in optimization problems. It is vastly inclined in the applications of structural and multidisciplinary optimization, neural Computing, feature selection, engineering design, and image processing.
5.17. Elephant Herding Optimization
Elephant Herding Optimization (EHO) [126] is an important populace-based algorithm that was introduced for disentangling optimization challenges. In this mechanism, the elephants in every group are notified of their present position and matriarch through the group notifying the operator. It is developed by the accomplishment of the disentangling handler, which can enhance the population assortment at the later search phase. EHO maintains an efficient consonance between exploitation and exploration with certain enhancements in the method. It is commonly used in the applications of multilevel image thresholding, distributed systems, Static drone placement, wireless sensor networks, and energy-based localization.
| Algorithm 16: Bat Algorithm |
|---|
| Steps: A1. Start the process A2. Initialize bat populace and objective function A3. Elucidate beats amount A4. Set beat rates and intensity A5. While the condition is true, maximum iterations fail, then A6. Initiate new solutions by regulating frequencies and notify the velocities and locations A7. If a chaotic value is more than beat rates, then A8. Choose a result amidst the finest one and initiate a communal answer among the chosen finest result A9. Else, originate a recent result by winging unevenly A10. If the random value is smaller than the intensity and the unbiased part is less than the number of bat populace, then A11. Attain the new solutions and extend the pulse rates and narrow the loudness A12. Grade the bat and finalize the best solution A13. End the process |
| Algorithm 17: Elephant Herding Optimization |
|---|
| Steps: A1. Start the process A2. Set the parameters A3. Calculate the fitness value A4. Enhance the matriarch’s positions with 2-opt A5. Implement the clan or group notifying operator A6. Implement 2-opt to improve elephant’s positions A7. Implement the separating operator A8. Evaluate the fitness by incrementing the generation A9. If the Generation is smaller than the maximum generation, then A10. Move to step 4, else A11. Return an optimized solution A12. End the process |
5.18. Glowworm Swarm Optimization
Glowworm Swarm Optimization (GSO) [127] is an emphatic population-based meta-heuristic algorithm that imitates the glow habits of glowworms, which can successfully acquire all the utmost multimodal functions. The glowworm swarm optimization (GSO) algorithm is one of the intelligent algorithms that was proposed by Krishna Nand and Ghose, the Indians in the year 2005. The GSO algorithm is delightful at clarifying the continuous optimization problem, which was efficiently used for the collective robot, multimodal function optimization, network sensor layout, cluster analysis, and so on. It is commonly used in the applications of routing, swarm robotics, image processing, and localization problems.
| Algorithm 18: Glowworm Swarm Optimization |
|---|
| Steps:A1. Start the processA2. Initialize the swarm glowwormA3. Calculate objective functionA4. Evaluate the glowworm and find its neighbor, A5. Calculate the probabilityA6. Update the movement of glowwormsA7. By using the local-decision range method, update the decision radiusA8. Check for maximum iteration, if true, output the solution, else go to step 3A9. After the output step, the irradiance value change is true means go to step 1 for other processes, else, go to step 8. |
5.19. Invasive Weed Optimization
Invasive Weed Optimization [128] is a significant population-based nature-enthused metaheuristic, enthused by the pandemic artifice of weeds was propounded by Alireza Mehrabian and Caro Lucas in the year 2006. An invasive weed meta-heuristic algorithm locates an extensive optimum of a mathematical function through echoing congruency and randomicity of the weed’s colony. Weeds are potent herbs in nature, and their threatening growth habits are a crucial warning to crops. It is very combative and adjustable to several environmental revolutions. It has the characteristics of a robust optimization concept. This algorithm follows the obstruction, resilience, and randomicity of a weed community in a pattern. A phenomenon inspires this mechanism in agricultural areas known as colonies of invasive weeds. It is broadly exploited in the applications of robust optimization, wireless sensor, soft computing, and training feed-forward neural networks.
| Algorithm 19: Invasive Weed Optimization |
|---|
| Steps: A1. The major populace initialization process started with a finite number of seeds that were allocated in the search space. A2. The imitation process begins with each germ turning into a blooming herb and delivers the germs that lean on their strength value. A3. Spectral expansion performs its process by delivering seeds in groups with the support of mean and standard deviation (SD) A4. This transformation convinces that fall of grain in the field reduces nonlinearly at each step, leading to more fit plants and eradicating inappropriate plants, and displays the transfer mode from r[i] to the selection of K[j]. A5. Combative indigence happens if the numbers of grasses violate the maximum number of grasses in the colony (Pmax[n]), the grass with the worst fitness is deleted from the colony so that a constant number of herbs remain in the colony. A6. This process abides down to the utmost number of repetitions is achieved, and then the minimum colony cost function of the grasses are stored. |
5.20. Shuffled Frog Leaping Algorithm
An imitation process of a meta-heuristic called the shuffled frog-leaping algorithm (SFLA) [129] was proposed mainly for elucidating conjugable optimization challenges. The SFLA is a notable populace-based communal comb analogy enthused by habitual imitations. Eusuff and Lansey developed the shuffled frog leaping (SFL) algorithm in the year 2003. It imitates the behavior of frogs when piercing for the location with an exhaustive amount of food (Eusuff et al ., 2006). The procedure of SFL simultaneously tackles an equitable communal forage in each group of memes. It is generally used in the applications of statistics, mathematical programming (such as location selecting, network partitioning, routing, scheduling and assignment problems, etc.), and computer science (including pattern recognition, learning theory, image processing, and computer graphics, etc.).
| Algorithm 20: Shuffled Frog Leaping Algorithm |
|---|
| Steps: A1. Start the process A2. Initialize the parameters A3. Generate a random populace (frogs) and Calculate fitness value A4. Sorting populace of fitness value in descending order A5. Divide the populace into memeplexes A6. Apply local search and update the worst frog of each memeplexes A7. Shuffled the obtained memeplexes A8. If termination is true, determine the best solution, else go to step 4. A9. End |
Summarizing it with several bio-inspired algorithms, addition to that, it is widely used in a variety of domains with real-time applications. It is analyzed that the various algorithms will be used in a variety of scopes in future research. Regardless of its support in the optimization area, it is highly relevant to some of the application areas, such as social networking, data analysis, health care, medicine, cybersecurity, and some innovative gaming sector. Several other application areas of bio-inspired computing include neural networks, bio- degradability prediction, cellular automata, nascent systems, artificial immune systems, portraying the graphics, network communications and protocols, membrane computers, volatile media, sensor networks, learning classifier systems, and robot design. A lot of real-world applications can be elucidated as optimization challenges where algorithms are necessary to have the capability to search for the optimum value of the issues. Several traditional methods are feasible for incessant and conflicting functions.
A deep learning approach with a bio-inspired algorithm is used in the diagnosis process of liver cancer [130]. Bioinspired deep learning [131] tackles the complex problem of business intelligence that achieves extended data mining and expertise from random-size datasets. Prognosis of Cardiac Disease procures more priority in the field of medical diagnosis. Bio-inspired algorithms [132] have been upgraded to solve combinatorial optimization problems, so it entices several researchers to investigate Cardiac Disease problems. The metaheuristic algorithms are developed mainly to answer the problem that arises in the future, where the conventional methods cannot explain or, at least, be challenging to decipher. Table 5 shows the use of various bio-inspired algorithms in the health sector field for accurate diagnosis and prediction. Several traditional methods are feasible for incessant and conflicting functions.
| Algorithm | Accuracy | Application |
|---|---|---|
| Particle Swarm Optimization and Firefly Algorithm | 93%-97% | Diagnosis of breast cancer [133] |
| Artificial Immune System | 94% | Detection and prediction of osteoporosis [134] |
| Cuckoo Search Algorithm | 70% | Respiratory disease detection from medical images [135] |
| Grey Wolf Optimization | 94.83% | Diagnosis of Parkinson’s disease [136] |
| Firefly Algorithm | 76.5% | Heart disease prediction [137] |
| Differential Evolution | 83% | Prediction of heart disease [38] |
| Moth–Flame Optimization, Firefly Optimization, Artificial Bee Colony Optimization, and Ant Colony Optimization |
89.02%, 86.64%, 84.86%, and 78.63% | Diagnosis of pulmonary emphysema [138] |
| Artificial Plant Optimization Algorithm | 95.41% | Detect heart rates and find the presence of heart disease [139] |
| Bat Algorithm | 97.3% | Classification of white blood cells [140] |
6. CHALLENGES AND FUTURE DIRECTIONS
Nowadays, Artificial Intelligence (AI) plays a significant job in medical care. Today’s world is severely affected by COVID-19, so the need for technology innovation through data analytics, AI, ML, and its sub-models of deep learning has been a major need in this pandemic. Another crucial area of AI that is effective at optimizing is evolutionary computing. Since ML, DL and EC are the most effective learning and optimization technologies, respectively, in the AI field, their advances are closely interwoven and considerably benefit from one another. The role of evolutionary computing [141] is important in data processing, model searching, training, evaluating, and utilizing for optimizing deep learning through bio-inspired optimization algorithms. Data mining and analytical modeling are now varsities for medical experts to learn about for future unknown diseases. The major challenges for deep learning are collecting data, working with interpretability and efficiency, integrating with other traditional methods, maintaining the imbalanced labels with multimodal data, and proposing new models with other interdisciplinary studies. To do this kind of work in the future, the deep learning method can be used for feature extraction, classification, and also with a combination of both. The important and powerful deep learning model, such as convolutional neural network (CNN), can be enhanced with more layers to develop neural architecture specifically for medical image analysis. The deep learning model can also be enhanced with novel data pre-processing, augmentation techniques, and hyperparameter optimization that will provide us with an additional performance from a network in terms of learning rate and dropout rate. These are the key aspects of successful deep-learning methods in medical care. In 2022, deep learning methods can be used for the implementation of projects by various companies, such as chatbots, forest fire prediction, digit recognition systems, image caption generators, traffic signs recognition, credit card fraud detection, movie recommendation system, virtual tracing system, drowsiness detection system and customer segmentation.
Future work will focus on the following points:
- Large-scale optimization for model training in medical datasets
- Evolutionary multitasking with the support of bio-inspired algorithms for optimization
- Optimization of new deep learning architectures in the healthcare sectors
- Multimodal optimization for deep learning ensemble models in the prediction of various human diseases
- The exploitation of problem-specific knowledge during the search for research papers in the medical field
- Exploration of alternative optimization domains for predicting diseases with more accuracy
- Inclusion of multiple implementations–related objectives, ideas, and motivation
- Reuse of learned knowledge towards modular learning in healthcare sectors
If we continue to work on the above challenges and future directions, deep learning models will accelerate breakthroughs across all medical-related issues with the applications of machine learning and artificial intelligence.
CONCLUSION
The technological evolution with the support of the Deep learning model in the Cardiac and medical fields guides humans to look over the AI-driven field. Data listed in the paper shows that deep learning has emerged as the latest top picker for researchers. Cardiac disease classification using deep learning models guides researchers to do more innovation by developing a new methodology. With the support of deep learning models, cardiac disease reviewed publication shows the comparison of different classification methods' accuracy rates in the detection or prediction process of it. The important features of the cardiac disease detection process from five different countries show that the researchers are utilizing it from several popular datasets, such as UCI (Cleveland, Hungary, Switzerland), Framingham Heart Study, Statlog Heart Disease, and Cardiovascular Health Study (CHS). The present study on deep learning models with cardiac disease indicates that the accuracy can be enhanced by embedding it through Bio-Inspired algorithms. Bio-inspired computing even has an immense reach to develop and spread across various research societies. The algorithms listed above must create a spacious impact on future-generation computing. It has been found that biocomputing provides a natural way to solve the problem of humans and lots of animals in nature.
In the future, Cardiac Disease classification with Deep learning and Bio-Inspired algorithm combination will be significantly increased. Deep learning is a fast-growing application of machine learning with the latest enhancement guides to do more research on predictive and diagnostic models that can save many patients and lead their life in a quality way. Also, with the emergence of novel deep learning methods, it can be proposed by the features of Cardiac Disease to predict Hypertrophic Cardiomyopathy (HCM) accurately at an early stage which is one of the Cardiomyopathy types. By doing this, it can save many numbers of lives and also deduct the cost problem for average-income people.
LIST OF ABBREVIATIONS
| WHO | = World Health Organisation |
| HOBDBNN | = Higher-Order Boltzmann Deep Belief Neural Network |
| HRFLM | = Hybrid Random Forest with A Linear Model |
| DE | = Differential Evolution |
| ANN | = Artificial Neural Network |
| SVM | = Support Vector Machine |
| KNN | = K-Nearest Neighbor |
| DBN | = Dynamic Bayesian Network |
| SVM | = Support Vector Machine |
| CHS | = Cardiovascular Health Study |
| RSA | = Random Search Algorithm |
| ANNs | = Artificial Neural Networks |
| ELM | = Extreme Learning Machines |
CONSENT FOR PUBLICATION
Not applicable.
FUNDING
None.
CONFLICT OF INTEREST
The authors declare no conflicts of interest, financial or otherwise.
ACKNOWLEDGEMENTS
Declared none.

